التمثيل الجرافيكي للغات؟
2024-08-18 | @andrea، مُترجَمة من قِبَل الفريق العربي.
يعد وضع العناصر الجرافيكية بجانب التسميات النصية خدعة تصميمية رائعة - فهي تساعد عقلك على تخطي بعض الخطوات عند التنقل في واجهة المستخدم: فبدلًا من قراءة التسمية يتمكن معرفة ما يفعله الزر على الفور بمجرد إلقاء نظرة على الأيقونة.
هذا هو السبب وراء وجود أيقونة مرافقة لمعظم الأزرار في موقعنا الإلكتروني – ويمكنك فقط تخيل مدى سهولة ذلك في العمل على المشروع! أستطيع التنقل بسهولة عبر أي نسخة لغوية دون فهم كلمة واحدة منها، فقط لأنني أتذكر الأيقونات التي تميز كل زر.
هذا أيضًا سبب وضع العديد من واجهات المستخدم أعلامًا بجانب أسماء اللغات. لكن هل هو حقًا نهج جيد؟ فبعد كل شيء، تمثل الأعلام الدول وليس اللغات – وإذا لم تقنعك التعقيدات الأيديولوجية والسياسية لخلط هذين المفهومين، فالمشاكل العملية ربما ستفعل: اللغات ببساطة لا يمكن أن تُطابق واحدًا لواحد مع الدول.
أول مثال يخطر على البال: أي علم يجب أن يمثل اللغة الإنجليزية؟ لقد نشأت في 🏴 إنجلترا، لكنها تُتحدث أيضًا أو تعد رسمية في باقي المملكة المتحدة 🇬🇧، وفي الولايات المتحدة 🇺🇸، وأستراليا 🇦🇺، وكندا 🇨🇦، والهند 🇮🇳، وغيرها الكثير. لماذا نختار واحدًا على الآخر؟ إذا اخترنا مكان المنشأ، فهل سيعرف معظم الناس علم إنجلترا؟ وإذا اخترنا حسب حجم السكان، ألن يعتقد الناس أن علم الهند يشير إلى اللغة الهندية بدلاً من الإنجليزية؟ تظهر قضايا مشابهة مع لغات أخرى. أي علم يجب أن يمثل الإسبانية؟ 🇪🇸 إسبانيا، 🇲🇽 المكسيك، 🇦🇷 الأرجنتين، 🇨🇴 كولومبيا؟ وأي علم يجب أن يمثل البرتغالية؟ 🇵🇹 البرتغال، 🇧🇷 البرازيل؟ وأي علم يمثل العربية؟ 🇸🇦 السعودية، 🇪🇬 مصر، 🇮🇶 العراق، 🇱🇧 لبنان؟
هناك العديد من اللغات التي لا تُعترف بها كلغات رسمية في أي دولة. بعض مجموعات المتحدثين، مثل السليزيين أو الباسك، لديهم علم لمنطقتهم، بينما آخرون، مثل متحدثي اللادينو، لا يمتلكون ذلك – بل لا يقطنون حتى في منطقة واحدة. بعض اللغات المصطنعة قد تمتلك علَمًا، مثل الإسبرانتو، لكن البعض الآخر ببساطة لا يمتلك. وحتى إذا وُجد مرشح جيد ليمثل علَمًا، فقد لا يكون مقبولًا عالميًا من قبل متحدثي اللغة، وقد يكون من الصعب استخدامه – على سبيل المثال، كان بإمكاني بسهولة إضافة رموز أعلام الدول في هذا النص، ولكن تضمين علم الإسبرانتو أو الباسك في نص يتطلب مجهودًا أكبر بكثير.
لقد قام الناس بتصميم أعلام لتمثيل اللغات بشكل أفضل من أعلام الدول – على سبيل المثال من خلال دمج عناصر من أعلام الدول التي تُتحدث فيها اللغة. إليك فيديو ممتع يستعرض مجموعة من الأفكار:
مع ازدياد عدد النسخ اللغوية لمشروعنا، كنا نناقش أفكارًا لجعل العثور على النسخة المطلوبة أسهل – بدون استخدام أعلام الدول.
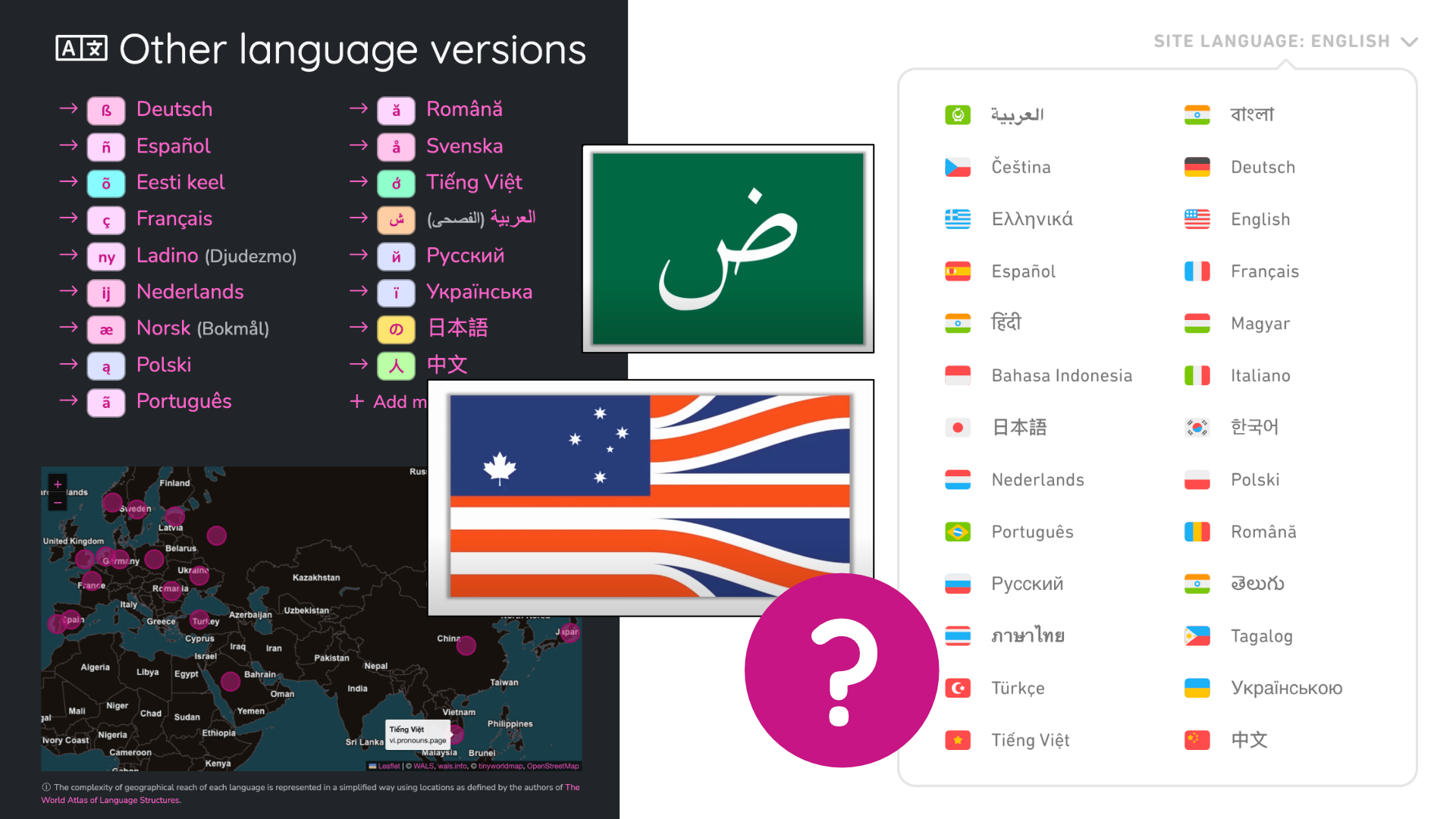
لقد أنشأت نموذجًا أوليًا لنهج نقوم فيه باختيار حرف واحد من لغة معينة يمكن أن يمثلها – على سبيل المثال ß للألمانية، ñ للإسبانية أو ą للبولندية – ونضعه على خلفية بلون يمثل عائلة اللغة – مثل الجرمانية، الرومانسية أو السلافية.

هذا النهج ليس مثاليًا أيضًا. إنه لا يزال اختيارًا تعسفيًا جدًا: لماذا لا نستخدم ł للبولندية؟ هل ينبغي أن تحصل السويدية على å، أم يجب أن تحصل النرويجية؟
الأبجدية الإنجليزية مملة نوعًا ما، فهل نختار حرفًا لاتينيًا عشوائيًا، أم ربما نغامر بعدم الفهم ونستخدم الحرف التاريخي þ؟
هذه الأحرف أقل قابلية للتعرف عليها من الأعلام التي اعتدنا رؤيتها تمثل اللغات – وبينما قد تكون فكرة جيدة على المدى الطويل، فإنها لا تساعد كثيرًا على المدى القصي
نهج آخر قمنا بالبحث فيه كان استخدام خريطة. بينما يمكن أن يتواجد متحدثو أي لغة في أي مكان، فمن الممكن عمومًا تحديد منطقة عامة حيث تُتحدث اللغة بشكل شائع.
لسوء الحظ، العثور على مجموعة بيانات مفتوحة المصدر لهذه المناطق ليس بالأمر السهل، وحتى لو كان لدينا ذلك، لا يزال يتعين علينا التعامل مع قضايا مثل التداخل بين المناطق، أو بعض المناطق التي تكون صغيرة جدًا للنقر عليها بينما تغطي مناطق أخرى قارات بأكملها.
بدلًا من ذلك، جربنا استخدام مجموعة بيانات من إحداثيات خط العرض/خط الطول البسيطة لكل لغة من الأطلس العالمي لهياكل اللغة، حيث يتم تمثيل كل لغة بنقطة واحدة على خريطة، في "مركز الثقل" العام كما اختاره اللغويون الذين أنشأوا تلك المجموعة.
ولكننا لا نزال لم نتخلص فعليًا من المشكلة الرئيسية في خلط اللغات مع الدول – بينما قد يساعد ذلك متحدثي البولندية على العثور بسرعة على النقطة في وسط بولندا، ربما لن يكون من الواضح للمستخدمين من الولايات المتحدة البحث حول إنجلترا.
وأين نضع حتى لغات مثل الإسبرانتو أو توكي بونا؟
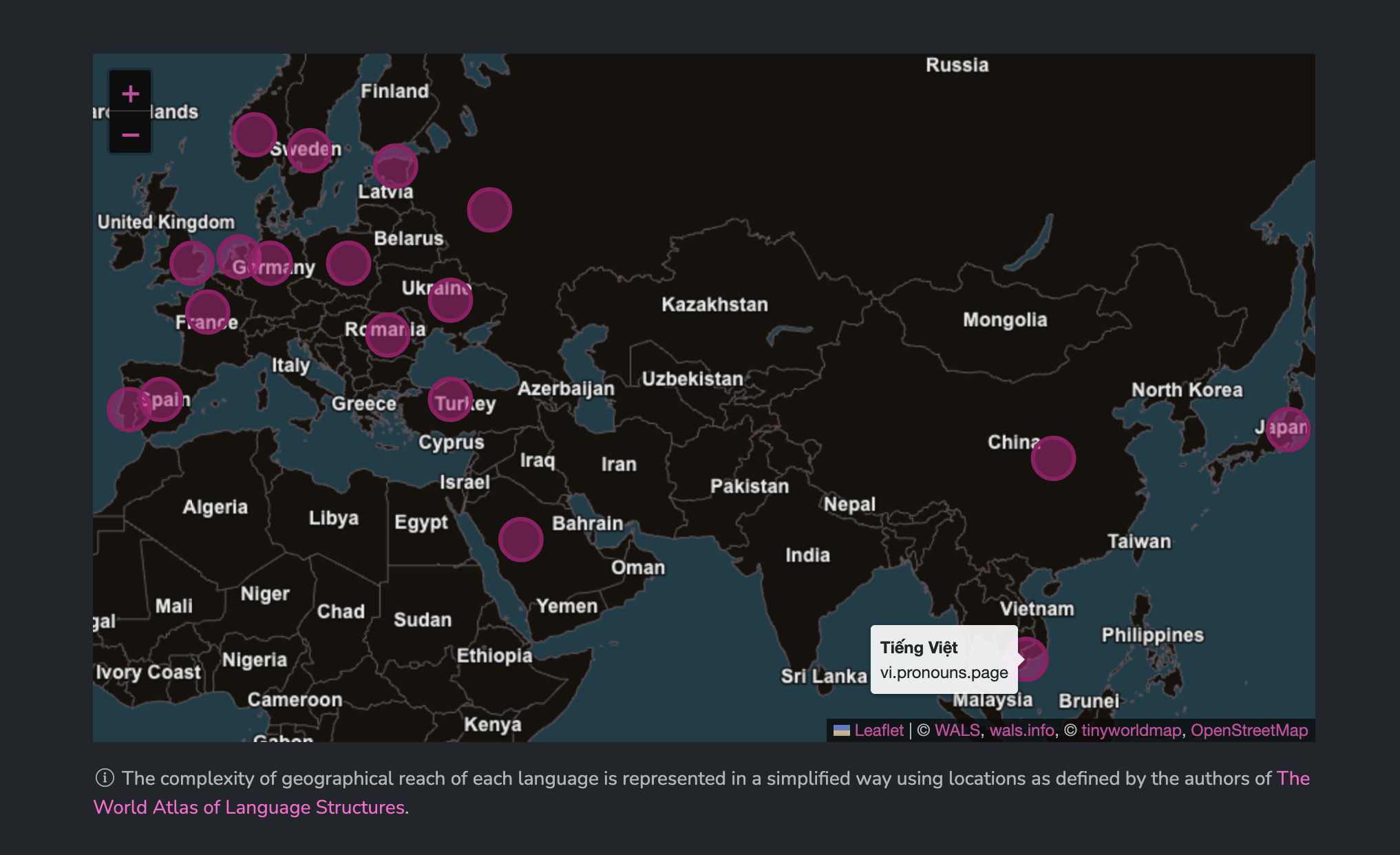
هذه الخريطة ليست مخصصة لرسم خريطة دقيقة للغات، بل الفكرة كانت أن تكون أداة إضافية للمساعدة في تقليل الارتباك عند زيارة الصفحة ورؤية قائمة متزايدة من اللغات دون أي أدوات رسومية إضافية (مثل الأعلام).
يمكن لبعض المستخدمين العثور فورًا على اللغة التي يبحثون عنها بمجرد إلقاء نظرة على الخريطة – بينما يمكن للآخرين الاعتماد على قائمة بسيطة للغات.
ولكن في النهاية، قررنا أن هذا النهج بعيد جدًا عن الجيد ليتم وضعه فعليًا على الموقع.
ما انتهى بنا المطاف بتنفيذه على الصفحة الرئيسية في pronouns.page، هو ببساطة إضافة بعض الأدوات المساعدة إلى قائمة اللغات "الخام" الموجودة.
يمكننا استخدام قائمة اللغات المفضلة كما حددها المستخدم في إعدادات متصفحه – وإظهار بعض الاقتراحات في الأعلى؛ بهذه الطريقة، من المرجح جدًا أن يروا ما يبحثون عنه على الفور.
تحتها، توجد قائمة كاملة بدون أي عناصر رسومية إضافية، ولكن الآن تحصل على عامل تصفية – يمكن للمرء فقط البدء بكتابة اسم اللغة التي يبحث عنها (إما الاسم الداخلي أو الخارجي) أو رمز ISO الخاص بها – وسيجدها مباشرة.
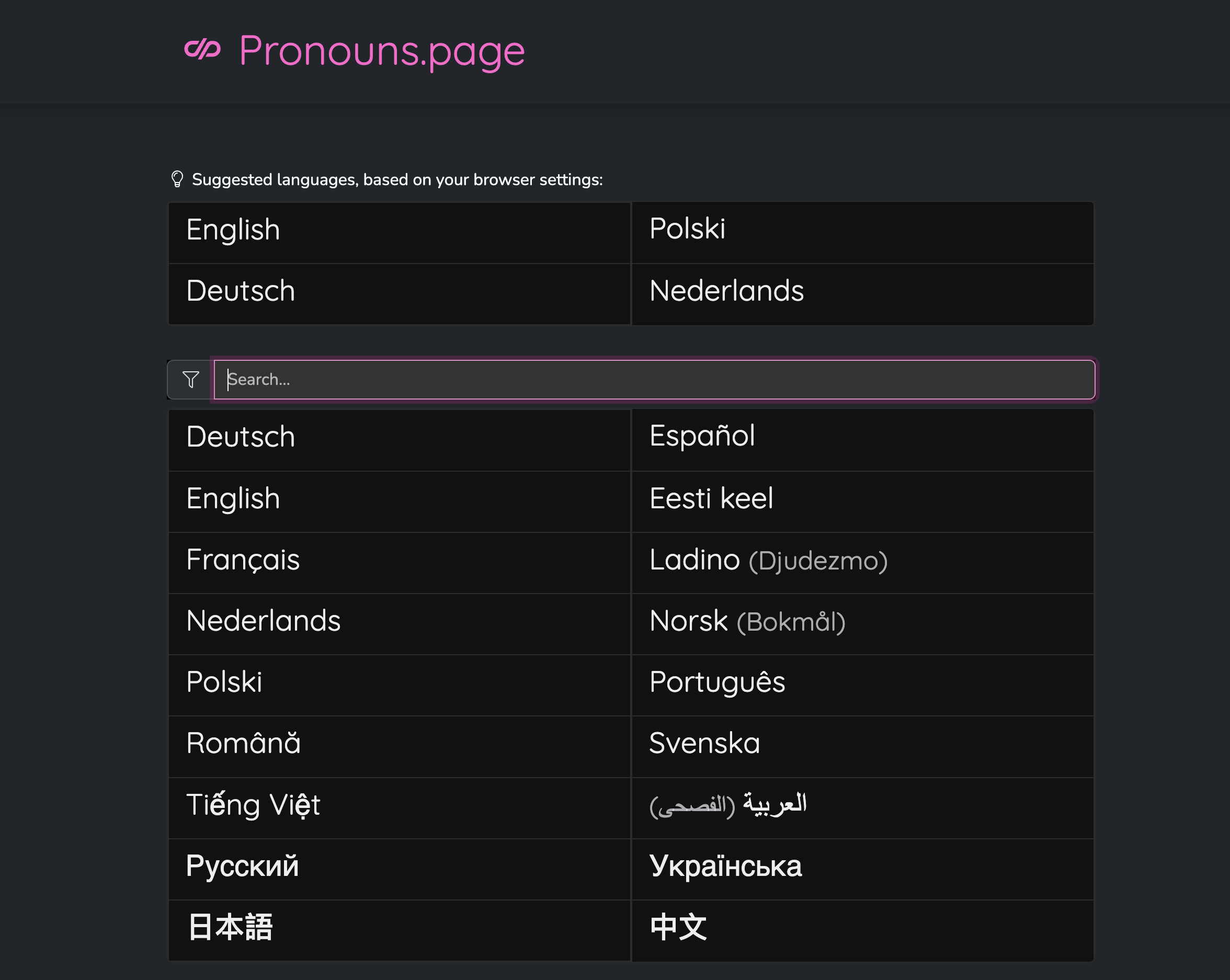
القائمة ليست مثالية أيضًا. كيف يمكنك حتى فرز اللغات أبجديًا إذا كانت تستخدم كتابات مختلفة؟
يمكنك استخدام الترجمة الحرفية لأسمائها، كما تفعل ويكيبيديا، ولكنه لا يزال نهجًا أوروبيًا بعض الشيء ولا يأخذ بعين الاعتبار اللغات التي لها عدة ترجمات حرفية مثل التايلاندية.
يمكننا فرز اللغات حسب شعبيتها (على سبيل المثال، عدد البطاقات في قاعدة بياناتنا)، ولكن بينما قد يجعل ذلك من الأكثر احتمالًا العثور بسهولة على لغتك لعدد أكبر من الناس في المتوسط، فإنه لن يجعل العثور عليها سهلًا في العموم.
حاليًا، نحن نعالج النصوص اللاتينية وغير اللاتينية بشكل مختلف، بسبب تكوين وشعبية اللغات الحالية، ولكن من المحتمل أن يتغير ذلك مع ظهور المزيد من النسخ.
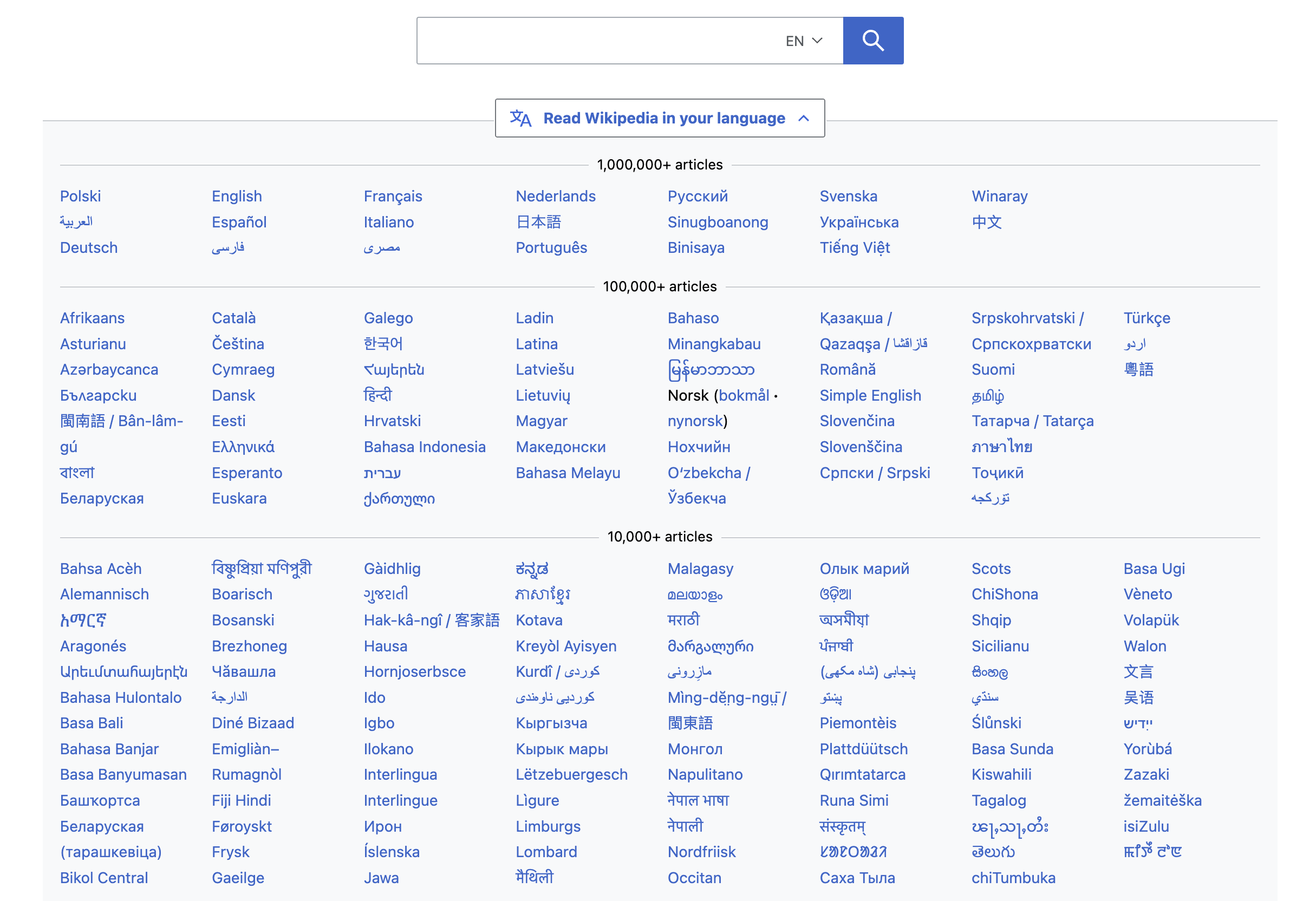
بالطبع، نحن لسنا قريبين من ويكيبيديا. مع وجود 18 نسخة لغوية لـ Pronouns.page منشورة حاليًا، كل هذا ليس مشكلة _ضخمة_، يمكن للناس بسهولة فحص القائمة بالكامل والعثور على ما يبحثون عنه.
ولكن بالنظر إلى أن هناك أيضًا 47 قناة لغوية على خادم Discord الخاص بنا، في مراحل مختلفة من الإكمال، فإن السؤال أصبح أكثر أهمية مع مرور الوقت.
لن تحل أي من الأدوات المذكورة أعلاه المشكلة بالكامل، ولكن بمجرد دمجها جميعًا معًا، يمكن أن تجعل تجربة المستخدم أسهل بكثير.
إذاً، ما رأيكم جميعاً في هذه المسألة؟ هل لديكم أفكار أفضل؟ هل هناك نهج من شأنه أن يحل جميع المشاكل ويصبح معيارًا مفيدًا لإدراج اللغات في واجهات المستخدم؟ نحن منفتحون جدًا على التجارب!
تفاعل:
شارك:






